Здравствуйте, уважаемые посетители блога Дело в Сети. Здесь мы поговорим о том, где брать бесплатный контент. Эта информация может быть полезна веб мастерам, продвигающим свои сайты, и тем, кто планирует зарабатывать на Яндекс Дзен.
Где брать бесплатный контент
Сохранение контента с выпавших из индекса сайтов
Полностью бесплатный метод получения уникального контента – брать его с уже не работающих сайтов. Ежедневно тысячи доменов (по данным доменных регистраторов) освобождаются по истечении срока продления. Среди них можно найти сайты с контентом, который подойдет для наполнения ваших каналов на Дзене.
- Процесс заключается в следующем:
- Поиск освободившихся доменов.
- Анализ и отбор сайтов, с каких будем брать контент.
- Получение статей с сайтов.
- Проверка полученного контента на уникальность.
Поиск доменов
Для поиска освободившихся доменов можно воспользоваться любым сервисом, предоставляющим список освобождающихся доменов. Я использую mydrop.io. Регистрируемся там. Затем открываем на главной странице фильтр В фильтре выбираем: Зона ru Статус – Свободные
Задаем количество HTML файлов. Данный сервис сохраняет сайты у себя для продажи архивов. Поэтому в фильтре можно выбрать, сколько файлов в архиве с сайтом. Этот параметр позволяет задать ограничение на количество html файлов, т.е. по сути сколько на сайте было веб- страниц, без лишних файлов (изображения, файлы css, js и т.д.).
Задавать количество страниц имеет смысл для того, чтобы отсеять огромные сайты, на тысячи и миллионы страниц, т.к. с вероятностью 99% это будут форумы, интернет-магазины, кино сайты, дорвеи, что угодно, но не статейники. Если страниц слишком мало, то там вообще может не быть контента (обычно это сайты визитки компаний). Я ставлю в этом параметре от 50 до 999. Можно экспериментировать.
- Язык – Русский.
- Не показывать с АГС
- Без склеенных
- SimilarWeb – от 1000.
Сколько было трафа на сайте при жизни (количество показов за месяц, т.е. от ~30 НЕ уников в день). Задаю, чтобы отсеять откровенный шлак. Если параметр не задавать, потенциальных сайтов будет больше, но придется их выискивать среди огромного количества шлака. % поискового – от 50. Задаем, чтобы с поиска трафа было хотя бы от половины. Надеюсь, что частично мы уже ответили на вопрос, где брать бесплатный контент?
Анализ сайтов
После применения фильтра появится таблица с доменами. Если навести курсор на домен в таблице – появится тайтл его главной страницы. Таким образом можно понять, подойдет домен или нет. Если домен заинтересовал, то уже можно открыть его описание. Там обычно скриншоты нескольких страниц с сайта, можно опять же визуально посмотреть, есть ли на сайте текстовый контент.
Поскольку домены, которые мы смотрим, уже не работают, то открыв их в браузере, увидим ошибку. В качестве альтернативы можно открывать сайты в вебархиве. В вебархиве открываем последнюю дату. Если видим заглушку регистратора домена, то смотрим более ранние даты, пока не будет видно сам сайт.
Дальше необходимо просто попереходить по ссылкам, убедиться, что на сайте есть статьи, и большая часть страниц с контентом доступна. После этого нужно статьи выборочно проверить на уник. Можно просто открыть 2-3 разных страницы и вбить любое предложение с каждой в кавычках в гугл и яндекс. Если точных совпадений не найдено, значит статья уникальная, и с такого сайта брать тексты можно.
Бывает и такое, что сайта вообще нет в вебархиве, либо отсутствует большинство нужных страниц (обычно сохраняются главная и категории, а внутряки с нужными текстами не доступны). В этом случае можно попробовать делегировать сайт на старые DNS. Для этого нужно узнать, на каком IP находился сайт, когда он еще работал. После чего локально делегировать домен на этот IP адрес. В случае, если сайт еще не удален с хостинга – он будет открываться с вашего компа, как обычно.
Что нужно сделать:
Переходим на сайт http://viewdns.info/iphistory/. В форму вбиваем домен. Находим строку с записью, где указан какой-нибудь хостинг. Обычно он соответствует дате примерно за месяц до самой верхней записи в таблице. Пример:
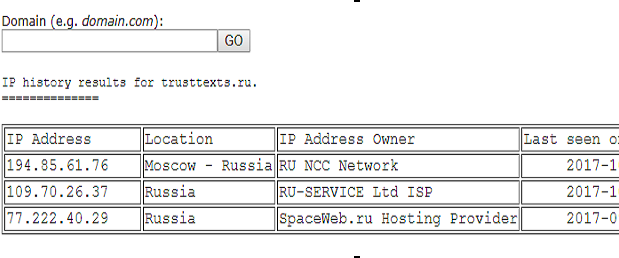
В данном случае самая нижняя строка, хостинг спейсвеб. Открываем в винде файл C:\Windows\System32\drivers\etc\hosts любым текстовым редактором. В файле hosts пишем: ip domain.com
Чистим кеш в браузере, и открываем повторно домен. Дальше возможно несколько вариантов. Либо сразу откроется сайт – тогда все ок. Либо будет редирект на www версию домена. В этом случае в hosts дописываем еще строку: ip www.domain.com. Либо будет висеть заглушка хостинга – значит сайт, увы, уже удален с хостинга, и сделать ничего не получится. Либо ничего не изменится и будет та же страница в браузере. Тогда нужно почистить кеш, если не помогло, то попробовать другой IP адрес.
Получение статей
Само собой, статьи можно руками скопировать, открыв сайт. Но в случае, если сайт доступен только в вебархиве, это займет слишком много времени – в вебархиве страницы очень долго грузятся, а также часть страниц не работает. В итоге выходит долго открывать каждую страницу, часть из которых еще и не работает. Поэтому проще выкачать сайт с вебархива любым софтом, и уже вытащить тексты с папки сайта на компе.
Есть несколько платных сервисов по выкачиванию сайтов с вебархива, например, r-tools.org. Можно выкачивать через них. Но если на сайте много страниц, то выйдет дороговато. К тому же, r-tools у меня через раз работает. Проще и дешевле самому выкачивать вот этим скриптом https://github.com/hartator/wayback-machine-downloader.
Естественно он будет работать только на своем сервере (VDS или дедик), если его нет, то можно попробовать запускать с локального сервера (опенсервер, денвер и т.д.). Скрипт работает на ruby, нужно поставить его, если не стоит. Установка зависит от операционной системы на сервере. Нужно просто погуглить, к примеру, «install ruby centos», «install ruby debian», ну или если локальный сервер, погуглить как ставить ruby на него.
После чего устанавливаем из консоли скрипт. Запускать в консоли так: wayback_machine_downloader http://example.com
По умолчанию, он сохранит страницы за самую последнюю доступную дату. Если в вебархиве за последнюю дату висит заглушка хостинга вместо сайта, то нужно найти дату, когда сайт еще работал. После этого запускать скрипт с дополнительным параметром: wayback_machine_downloader http://example.com —to 20100916231334
Число – это дата, которую можно скопировать из урла страницы в вебархиве. В таком виде скрипт будет выкачивать страницы с этой датой и ранее. Информация выше актуальна для вебархива. Объективных причин для выкачивания статей каким-то специальным софтом с сайтов, делигированных на ваши днс, не так уж и много. Статьи можно просто скопировать руками.
Единственное, бывает, что весь контент сразу не нужен, а сохранять все статьи долго и лениво, и хочется оставить это все на потом. Но сайт-то уже не работает, и может быть удален с хостинга в любой момент. Тогда будет логично выкачать сайт на локалку, чтобы использовать тексты с него в дальнейшем.
Есть много качалок сайтов. Отличаются только количеством мусора, правильностью воссоздаваемой структуры, полнотой сохранения файлов стилей, скриптов, картинок. По большому счету, нам нужны только html страницы, а остальное все не важно. Поэтому подойдет любая программа, которая вам нравится. Я использую либо wget, либо Offline Explorer. Wget – это консольная утилита. Идет по умолчанию на большинстве сборок линукса. Если у вас есть любой локальный сервер, дедик или VDS, то можете запускать его из консоли. Так: wget –r –l 0 http://domain.com
Сайт скачается без лишних стилей и картинок, в основном будут только нужные html файлы. Offline Explorer – более удобная программа под винду. Основное преимущество перед wget – визуальные настройки. Можно отключить выкачивание любых ненужных файлов, чтобы сохранялись только html страницы. Также wget на некоторых сайтах может сохранять не все файлы, с Offline Explorer такой проблемы замечено не было. Программа платная, но на просторах сети есть крякнутая Portable версия. Из выкачанных html файлов удаляем лишний код, оставляя только тексты и пересохраняем в формат txt.
Тем, у кого есть Content Downloader (можно самой базовой версии) – напишите отдельно. Скину шаблон, который позволяет сразу сохранять статьи с сайта в txt файлы без лишнего кода и в приемлемом для публикации в Дзен виде (без тегов и с нужной разметкой). В нем надо будет только поменять границы парсинга и ссылки, с которых парсить. Кряк этой программы не нашел, соответственно круг ее использования будет ограничиваться только теми, у кого есть или кто планирует приобрести лицензию. Поэтому и загромождать мануал здесь описанием работы с этим софтом смысла нет.
Переводы через Google Translate
Условно-бесплатный способ получения контента на любую тематику в любое время. Мало кто знает, но уже около года (с весны 2017) гугл обновил и сильно усовершенствовал алгоритмы машинного перевода. Это применимо только к переводам на отдельном сервисе https://translate.google.com.
Перевод через плагин в хроме будет по старым алгоритмам, и сильно отличается по качеству в худшую сторону. Подготовка контента для гугл перевода ничем не отличается от описанной в предыдущем разделе. Находим подходящий буржуйский сайт (я использую сайты на английском – много сайтов, адекватное качество перевода на русский с этого языка), после чего выкачиваем статьи одним из перечисленных выше способов (с помощью качалки и подготовки файлов вручную, либо шаблоном для Content Downloader’а).
Если текстов немного, можно сделать это и руками. Но если статей хотя бы от 100, то будут неизбежны проблемы с капчами и блокировками. Не говоря уже о том, что это попросту долго.
Поэтому был написан шаблон на Zennoposter, который приложен к раздаче. Шаб работает через прокси Tor’а, поэтому капчи и блокировки не появляются. В шабе нужно выбрать направление перевода, при необходимости можно писать свои регулярки для постобработки контента. Отдельная инструкция есть в раздаче.
Надо отметить, качество контента после перевода все равно далеко от идеального. Во избежание проблем с блокировками аккаунтов в Дзене, статьи нужно править. Обычно все правки сводятся к форматированию текста после переводчика (разбить на абзацы, поправить теги), поправить по смыслу корявые фразы. В среднем на 1 текст уходит 5-10 минут, в зависимости от объема. Это гораздо проще и быстрее, чем писать с нуля. Качество остается прежним (но зависит от изначального источника).
Качество перевода также сильно зависит от тематики и стиля изложения. Нормально выходит переводить обычные информационные статьи, различные эмоциональные рассказы с шутками и фразеологизмами – с этим у гугла проблемы, получается бред. Из того что пробовал – нормально
получается женская тематика и медицина.
Но вносить правки в тексты все равно нудно. Выход – нанять редактора на любом сайте фриланса. По оплате в районе 20-30р за статью (объемом 2000- 3000 знаков), мотивируя низкую цену количеством контента, которое будете заказывать.
Магазин контента
Если лениво искать контент самостоятельно, то можно недорого купить готовые статьи с вебархива. Цена всего 10-20р за целую статью. Ссылка на биржу: http://textnet.ru. На текстнете реально много статей, почти по любым тематикам. Статьи разбиты по рубрикам, что удобно для поиска контента по тематике вашего канала.
Тексты постоянно пополняются. Чтобы не пропустить новые статьи и первым их выкупить, можно подписаться на интересующую вас рубрику. При пополнении раздела на почту будет приходить оповещение.
Статьи не всегда попадаются качественные. Хоть админы и заявляют, что весь контент проверяется на качество, но по факту их понятие о качестве может кардинально отличаться от вашего. Желательно почитать аннотацию к статье перед покупкой. Совсем уж откровенный шлак будет видно.
Хотя владельцы биржи заявляют уникальность 90-100%, контент все равно лучше проверять на уник самостоятельно. Если уникальность будет меньше 90%, пишите в тикеты, чтобы вернули деньги за неуникальную статью на баланс.
Скан
Скан – отличный вариант условно-бесплатного получения контента. Есть два варианта.
Можно купить уже готовый отсканированный, распознанный и отредактированный контент. Продается не дорого, цена зависит от объема, в среднем от 3-5р за 1000 символов. Искать продавцов можно в Google, на различных seo форумах.
Второй вариант более долгий – это сканировать самостоятельно. Метод может показаться сложным и долгим, на самом деле тут все просто.
Для самостоятельного скана понадобятся 4 составляющие:
- Сканер. Если нету, можно не дорого купить на Avito – окупится с первых запущенных блогов.
- Программа ABBY FineReader, можно скачать в интернете.
- Книги/журналы для сканирования.
- Софт для проверки на уникальность.
Книги также можно дешево искать на Авито или барахолках. Можно по телефону позвонить и попросить сказать тираж и прочитать любое предложение из книги – проверяете сразу на уник, и можно покупать. Тираж искать не большой, меньше шансов что уже где-то опубликовано.
Может показаться что метод сложный, но по сути – стоимость б/у книг составляет 50-100р за книгу, а контента там будет на сотни статей, разбитых по 500-1500 символов. Такой блог можно вести пару месяцев и заработать несколько десятков тысяч рублей. Согласитесь, неплохо при вложении 100р за книгу, несколько телодвижений по ее поиску, пара часов сканирования.
Дешевый рерайт
Заработок в Яндекс Дзене составляет от 40 до 180р за 1000 дочитываний, отсюда можно рассчитать окупаемость по каждой статье. Скажем, у вас опубликовано 20 статей, суммарно 20 000 дочитываний за 10 дней, это по 2000 дочитываний на каждую статью, и 1800р на балансе (при среднем значении 90р за 1000 дочитываний). Можно посчитать что 1 статья принесла 180р.
Учитывая, что объем статьи у нас 500-1500 символов, а средняя стоимость рерайта составляет 30-40р за 1000 символов, наш ROI составляет 600%. Что является весьма выгодными инвестициями.
Искать рерайтеров можно на фриланс биржах, например work-zilla.com или fl.ru.
Примерное ТЗ на рерайт:
- Тематика проекта: Качественный рерайт статей.
- Тематика — Финансы
- Исходники даю (или ищите сами!). Суммарный объем 50к символов без пробелов. Оплата 30р/1к. символов б.п. Объем каждой статьи 500-1500 символов.
- Объем важно сохранять в данных значениях. К каждой статье свой заголовок.
- Уникальность от 90% по eTXT Срок до 3 дней.
- Желательно подобрать картинку к статье, вставить ее сразу после заголовка ссылкой на Яндекс Картинки (чтобы сразу был готовый контент для шаблона автопостинга)
- Формат – каждая статья в отдельном файле .txt
Плюсом при работе с заказом рерайта является то, что можно искать и заказывать контент под тренды, моделировать успешные сайты/блоги. Данный подход при достойном уровне качества имеет все шансы хорошо выстреливать и набирать хорошие просмотры. Минус – это финансовые вложения и соответствующий риск, что контент не взлетит.
На этом все о том, где брать бесплатный контент.